Web Scraping Medium Articles with Scrapy: From Simple to Advanced (part I)
Create a simple and efficient web scraper in a single script using a powerful framework in Python.

Introduction
There are many reasons to analyze blog posts and articles from one or several publishing platforms. The reasons may be from understanding the differences between different platforms, but also to understand some of the characteristics of top writers, trends and readers behavior and preferences.
However, before any data analysis can be made, we need to have the data in our hands! And that’s where web scraping comes to the rescue.
In this article, I’ll explore how we can use Python and Scrapy to build a very simple but powerful web crawler which scrapes article data from our neighbourhood platform Medium. It is so simple that we'll need to edit/create a SINGLE script, while being powerfully fast, efficient and with smart embedded functionalities.
In Part II, additional concepts from Scrapy will be used in order to better organize the code, make the data extraction process cleaner and more robust, while adding customized behaviors such as saving the scraped data to a database and dropping duplicate data.
If you want to see the full code first, you can check it here.
Objectives
- Show the basics of how Scrapy can be used for real world applications in a very simple (but powerful) manner.
- Build a simple web crawler to save Medium article’s data using Scrapy.
- Configure the web crawler so that it is efficient, ethical and robust at the same time, by taking advantage of Scrapy’s built-in functionalities.
- Define a crawling strategy so that the web crawler can optimize the number of requests.
- Save the scraped data in CSV.
Disclaimer:
This article is partly inspired by Otávio Simões' article "How to Scrape a Medium Publication: A Python Tutorial for Beginners". I stumbled on it while trying to scrape articles from Medium using Scrapy. One of the main difference between the current article and Otávio Simões' article is that he uses BeautifulSoup and I'm using Scrapy. I will go a bit further and add more features in the next parts of this article. I really recommend you to go see his work.
What is web scraping?
Web scraping is the act of extracting or “scraping” data from a web page, which can be used for a wide range of applications such as mining, processing or archiving information.
The general process is as follows. First the selected web page is downloaded or "fetched". Next the data is retrieved and parsed through into a suitable format. Finally we get to navigate through the parsed data, selecting the data we want to save.
The Web scraping process is fully automated, done through a bot which we call the web crawler or spider, but we need to define which data will be saved. Web Crawlers are created using appropriate software like Python and the Scrapy library.
What is Scrapy (and why it is incredible)
Scrapy is a free and open-source web-crawling framework written in Python. Originally designed for web scraping, it can also be used to extract data using APIs or as a general-purpose web crawler.
Although there are many different web scraping libraries in Python with different objectives, strengths and weaknesses, Scrapy is capable of taking web scraping to the next level. If web scraping is a knife, then Scrapy would be a swiss army knife, since it comes integrated with many different functionalities that can not only save time but also create robust and ethical web crawlers.
Why Scrapy is incredible to start learning web scraping:
- It comes with a starting project structure, so you don’t have to start from zero.
- You can easily separate your code according to its functionalities using the Separation of Concern principle.
- Optionally, your web crawler can automatically follow the directives set by the website being scraped, as described in the website’s robot.txt.
- You can create item pipelines to avoid duplicate data, save it in CSV or SQLite and many more!
- Without any custom line of code, you can add fixed or randomized crawling delays between each scraped page, to avoid overloading the server and causing headaches for the website administrators.
- You can enable AutoThrottle to automatically adjust the delays between requests according to the current web server load.
- Many more!
In a nutshell, with Scrapy you can build fast, efficient, robust and ethical web crawlers without actually having to start from zero.
Getting started with Scrapy
Scrapy is built using Python, so first you need to have Python 3 installed in your system. Then, to install scrapy you can run the following command in the command line:
pip install scrapy
Scrapy already provides many commands to create applications and use them. You can create a new Scrapy project by entering the directory where you’d like to store your code and run the following command:
scrapy startproject medium_scraper
By doing so, Scrapy will create an entire project template for us. However, since we want to build a VERY simple web scraper, we won't create an entire project. In fact, we'll create just a single script!
Scrapy already comes with a command to create a spider template for us with the following command:
scrapy genspider example example.com
This will generate a VERY simple spider, which is actually a class that inherits from the scrapy.Spider class. The name is the name of our spider, which can be used as an identifier. If we want to, we can remove the allowed_domains for simplicity and since our spider is very simple, this won’t cause any problems. Finally, the start_urls is where we inform the web pages that we want to start scraping.
And importantly, the parse function is the spider’s method of parsing the HTML data. From this, data can be scraped and hyperlinks can be followed through, enabling the spider to have dynamic behavior.
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(self, response):
pass
Let’s Scrape Medium Articles
First, I’ll define which data will be scraped and how it will be done. Then, codes and explanations for different parts of the spider will be provided.
What (and how) we will scrape
Web scraping consists of three main steps: fetching the page, parsing the HTML, and extracting the information you need.
Usually the third step is the most critical. Since I’m interested in extracting only the data that are of interest, I have to manually find and specify which parts of the HTML that contains the information to be extracted.
This can be done by going to the targeted web page and pressing the F12 key on the web browser to access the Developer Tools. By doing so, I can select an element of the web page to inspect and see which information I can use so that the crawler is able to find and extract this element’s data. This is illustrated in the image below.
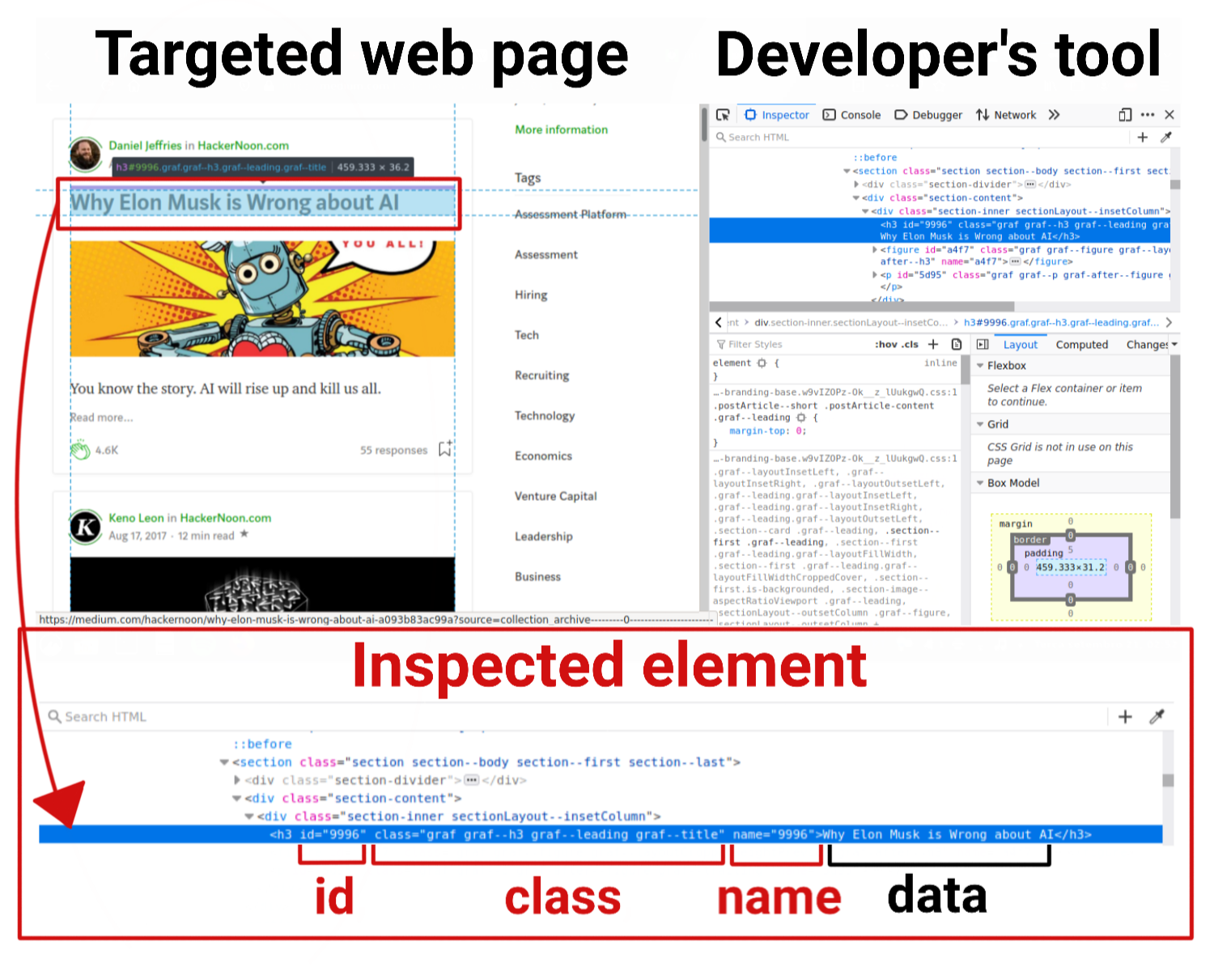
Every publication has its own archive organized by date. We can access it by typing “/archive” after the publication URL. As can be seen from the image below, we can even specify the year, month and day we want to access, but since it isn’t guaranteed that there will be articles published on the specified date, we’ll come with a strategy to deal with this problem and scrape the data in a smart and efficient manner.
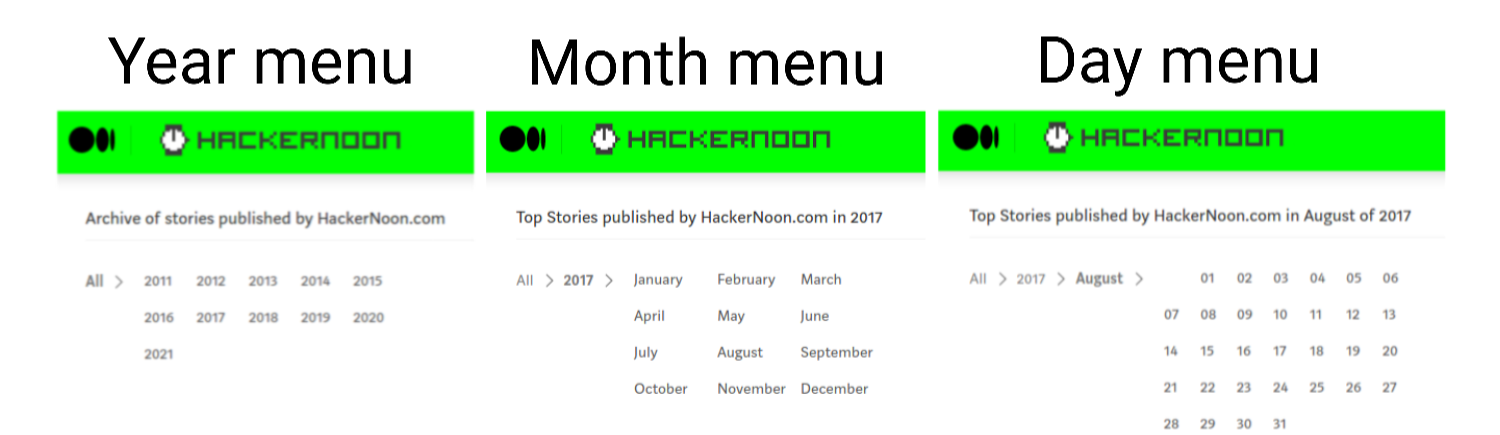
For convenience, I’ll scrape the Hackernoon articles published on Medium as an example. You can access it’s archive, which will be the starting point of our crawler, from the link below.
https://medium.com/hackernoon/archive
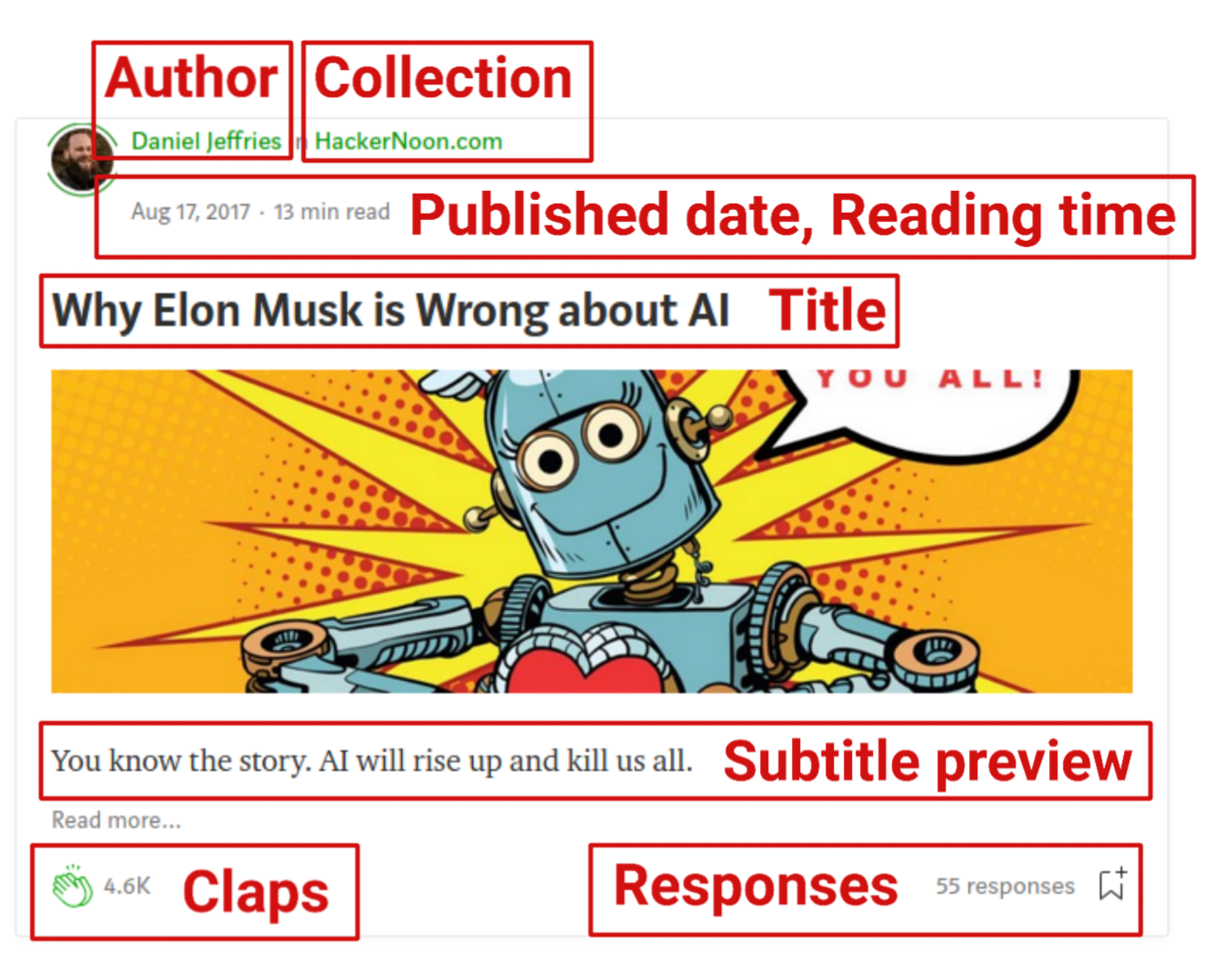
If we specify the year, month and day from the archive, we can see all the articles published on that specified date. Each article is represented by a container with information such as Title, Author, Published date, Claps etc, which are exactly the information we want to extract. This can be illustrated in the figure below.
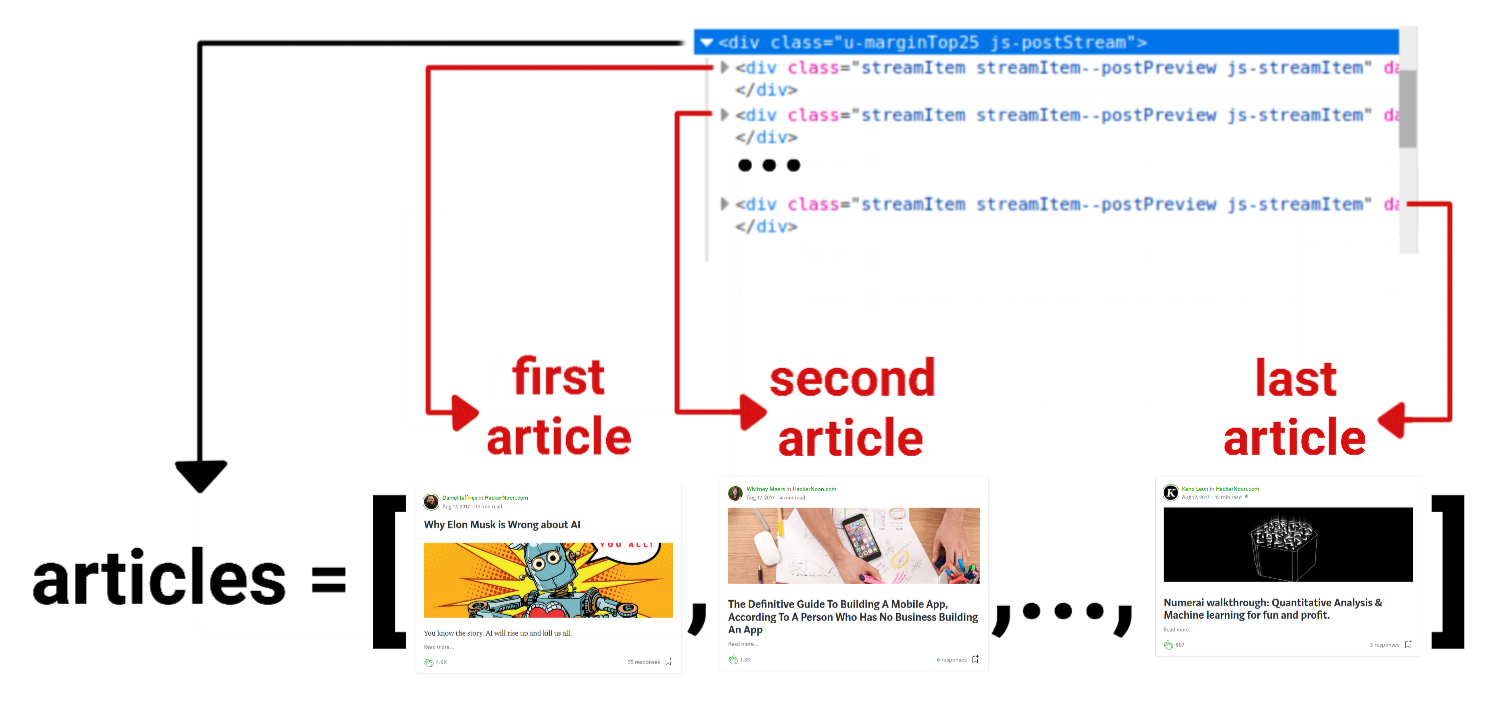
Since all these containers are inside a div element (described in XPath as /html/body/div[1]/div[2]/div/div[3]/div[1]/div[2]), we can collect all the containers inside this div by adding /* after its XPath.
By doing so, a list of containers with each article’s data is generated, as illustrated by the image below.
Then, with the list in hands, I can iterate over it and extract the data from each story, such as:
- Author name
- Title
- Subtitle preview
- Collection name
- Read time in minutes
- Number of claps
- Number of responses
- Published date
- Article URL
In addition to this data, the date when the scraping occurred will also be saved, since this can be valuable data to be used as reference when the data analysis is made.
The XPath for each element will be described in the spider’s data for brevity's sake.
Note: I won’t be going through how xpath and css selectors actually work, but there are resources at the end of this article if you want to check this out.
Let’s build our web scraper
In terms of pseudo-code, our spider will look something like this:
import the necessary packages
class ArticleSpider(scrapy.Spider):
/* SPIDER INFORMATION, CONFIGURATION AND TARGETED WEB SITES */
name = "spider_simple"
start_urls = ['link to the web page that will be scraped']
custom_settings = { … }
/* CODE FOR PARSING THE CALENDAR MENU */
def parse(self, response):
This is the starting point from our spider’s parsing
From each year in the calendar menu, parse the months
def parse_months(self, response):
From each month in the calendar menu, parse the days
def parse_days(self, response):
From each day in the calendar menu, parse the articles
/* CODE FOR PARSING THE ARTICLES, EXTRACTING AND PROCESSING DATA*/
def parse_articles(self, response):
create the list of articles
for article in articles:
Extract data1 and process the information
...
Extract dataN and process the information
Save the scraped_date
We’ll define some custom settings for our spider. Here, Scrapy really makes things simple, since many functionalities are already implemented:
- We’ll set AUTOTHROTTLE_ENABLED as True for the spider to be able to automatically throttle the crawling speed based on the load of the website it is crawling.
- We’ll set DOWNLOAD_DELAY to 1 to add a delay of 1 second between each web page request.
- But it is possible to go further and set RANDOMIZE_DOWNLOAD_DELAY to True so that this delay can vary between 0.5 DOWNLOAD_DELAY and 1.5 DOWNLOAD_DELAY. This randomness can offer a little help in disguising our spider, since the deterministic behavior of automated crawlers can arouse suspicion from the servers hosting the web page.
- I’ll also set ROBOTSTXT_OBEY to True so that our spider can follow the guidelines imposed by the web site
- Finally, I’ll set DUPEFILTER_CLASS to True to detect and filter duplicate requests.
What all this does is make our spider more efficient while being ethical and respecting the limits of the server hosting the web pages we’re scraping. All this by only setting 5 variables (some of them are actually set by default).
These custom settings can be coded in the settings script from a project (global settings) or directly in the spider script itself, in which case overrides the global settings, as seen below:
class ArticleSpider(scrapy.Spider):
name = "spider_simple"
start_urls = ['https://medium.com/hackernoon/archive']
custom_settings = {
'AUTOTHROTTLE_ENABLED': True,
'AUTOTHROTTLE_DEBUG': True,
'DOWNLOAD_DELAY': 1,
'ROBOTSTXT_OBEY': True,
'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter',
}
def parse(self, response):
pass
While the learning curve from Scrapy is indeed more steeper than libraries such as BeautifulSoup, built-in functionalities like these really can make a difference between simple HTML parsers and robust, efficient and professional web crawlers.
Code for navigating the calendar menu
The logic for parsing the calendar menu is quite simple:
- If the archive has publications spanning at least 2 years, we’ll start with the year menu. From the year menu, we collect the URLs from each available year and fetch them, calling a function to parse the months in each available year’s web page.
- From the month menu, we collect the URLs from each available month and fetch them, calling a function to parse the days in which an article was published.
- From the day menu, we collect the URLs from each individual day and fetch them. The result is a page that contains all the published articles from that specific day. It is this page that contains the information that we want to collect, so for each day in the menu we will call a function to parse the articles.
PS: In the first step, if the collection is very small or new, there may be some edge cases, which for brevity’s sake are already implemented in the parse function’s code.
Basically, instead of brute forcing every possible year, month and day combination, we parse Years -> Months -> Days -> Articles in search of the desired data to be scraped, treating in each situation the edge cases.
The code for parsing the calendar menu is shown below:
def parse(self, response):
year_div = response.xpath("/html/body/div[1]/div[2]/div/div[3]/div[1]/div[1]/div/div[2]")
year_pages = year_div.xpath(".//a/@href").getall()
if len(year_pages) != 0:
yield from response.follow_all(year_pages, callback=self.parse_months)
else:
yield from self.parse_articles(response)
def parse_months(self, response):
month_div = response.xpath("/html/body/div[1]/div[2]/div/div[3]/div[1]/div[1]/div/div[3]")
month_pages = month_div.xpath(".//a/@href").getall()
if len(month_pages) != 0:
yield from response.follow_all(month_pages, callback=self.parse_days)
else:
yield from self.parse_articles(response)
def parse_days(self, response):
day_div = response.xpath("/html/body/div[1]/div[2]/div/div[3]/div[1]/div[1]/div/div[4]")
day_pages = day_div.xpath(".//a/@href").getall()
if len(day_pages) != 0:
yield from response.follow_all(day_pages, callback=self.parse_articles)
else:
yield from self.parse_articles(response)
Code for scraping and preprocessing the raw data
Now that the spider has fetched the web page containing the desired data, we will parse the HTML and extract from it the desired data. However, this raw data sometimes is not always extracted in a standard type. For example, if the article is from the current year, it’s date format may be different from older articles. Or, if it has more than a thousand claps, the number may be represented as “1k” instead of 1000, which is a string instead of a number.
To avoid saving junk data, we will pre-process the data in order to guarantee that everything will be saved according to our standards.
The code for extracting each data and preprocessing it is shown below:
def parse_articles(self, response):
articles = response.xpath('/html/body/div[1]/div[2]/div/div[3]/div[1]/div[2]/*')
if len(articles) != 0:
for article in articles:
author = article.xpath('.//a[@data-action="show-user-card"]/text()').get()
str_read_time = article.xpath('.//*[@class="readingTime"]/@title')[0].get()
int_read_time = str_read_time.split()[0]
collection = article.xpath('.//a[@data-action="show-collection-card"]/text()').get()
title = article.xpath('.//h3[contains(@class, "title")]/text()').get()
claps = article.xpath('.//button[@data-action="show-recommends"]/text()').get()
if claps != None:
claps = claps.split()[0]
if type(claps) == str:
claps = text_to_num(claps)
responses = article.xpath('.//a[@class="button button--chromeless u-baseColor--buttonNormal"]/text()').get()
if responses != None:
responses = responses.split()[0]
subtitle_preview = article.xpath('.//h4[@name="previewSubtitle"]/text()').get()
published_date = article.xpath('.//time/text()').get()
try:
date_object = datetime.strptime(published_date, "%b %d, %Y")
year = date_object.year
except:
date_object = datetime.strptime(published_date, "%b %d")
year = datetime.now().year
day = date_object.day
month = date_object.month
published_date = datetime(year, month, day)
article_url = article.xpath('.//a[contains(@class, "button--smaller")]/@href').get().split('?')[0]
scraped_date = datetime.now()
yield {
'author': author,
'title': title,
'subtitle preview': subtitle_preview,
'collection': collection,
'read time': int_read_time,
'claps': claps,
'responses': responses,
'published_date': published_date,
'article_url' : article_url,
'scraped_date': scraped_date
}
def text_to_num(text):
d = {'K': 3}
if text[-1] in d:
num, magnitude = text[:-1], text[-1]
return int(Decimal(num) * 10 ** d[magnitude])
else:
return int(Decimal(text))
Some simple preprocessing were made to achieve some standardization, as described below:
- Reading time and number of responses was split and only the numeric part of it was extracted.
- The number of claps was expressed in an abbreviated form if the number was over 1000. The processing implemented converts the string to a corresponding integer.
- The published date was preprocessed so as to always inform the year in which the article was published.
- The article URL had the query string (the question mark in the middle of the URL) removed since it is redundant.
Scraping time!
With each part of our spider’s code defined, we can finally put it all together and start crawling! With scrapy, we can use a command line to select a spider and export the scraped data to a file. With this command, you can run a spider self-contained in a Python file, without having to create a project. See? It’s so simple you don’t even need to code it! The command is:
scrapy runspider your_selected_spider.py -o your_selected_directory/your_filename.csv
Although we specified in the command line that data will be saved in CSV format, we can also specify for it to be saved as JSON, JSON lines, CSV or XML by simply changing the format on the command.
The scraped data
After all this work, this is how the data looks like:
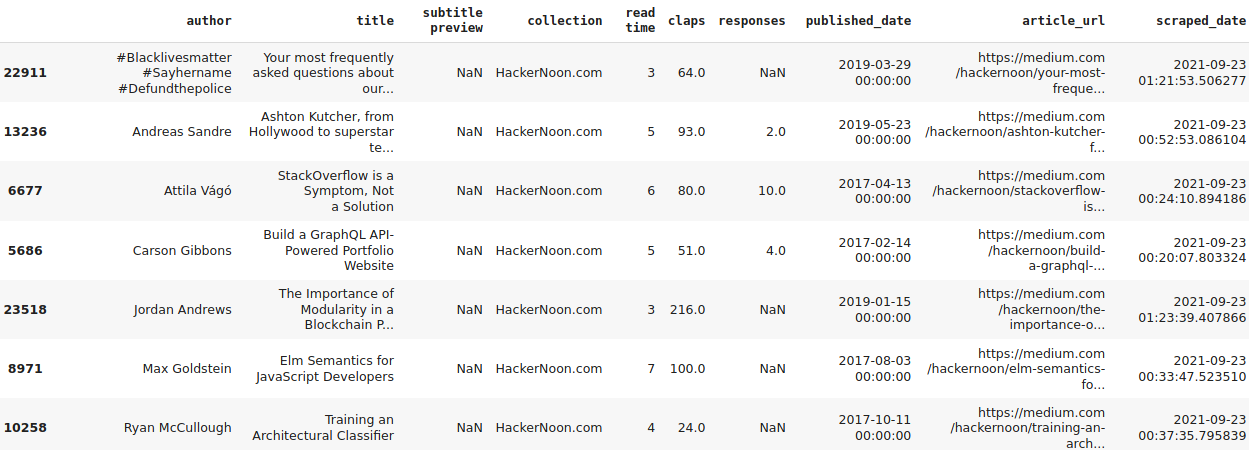
With this metadata from all these articles, many kinds of analysis can be made in order to capture trends and see are the characteristics of different authors and subjects, word clouds, etc, as can be seen in the image below.
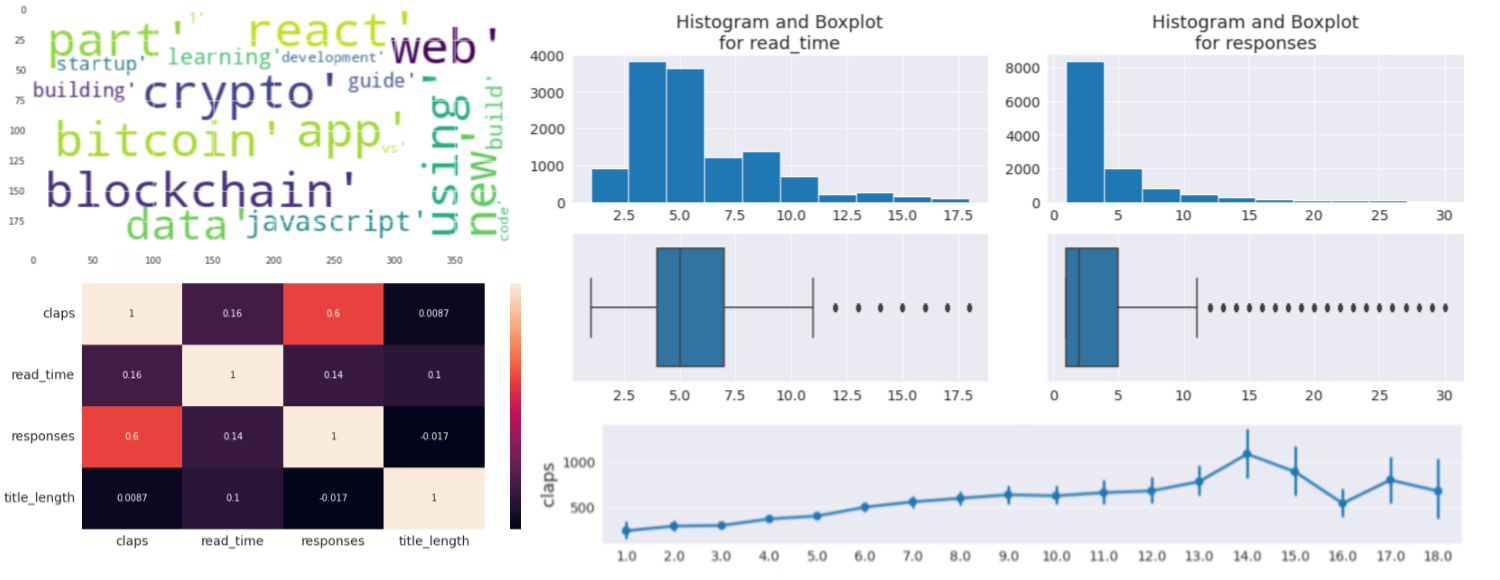
However, an exploratory data analysis isn’t in the scope of this article.
Conclusion
The aim of this article is to show that scraping real web pages shouldn’t be daunting, and even with a complete package such as Scrapy, you can create simple, efficient and ethical web crawlers. Although we can create smarter, more advanced and efficient spiders implementing good coding practices, everything should start from the beginning.
We could also take more advantage of Scrapy’s features and project structure and separate our code into different files according to its functionality, implementing the Separation of Concern principle for better software development. However, since we want to build a VERY simple spider, this goes beyond the scope of the current article.
Although data analysis of the scraped data could be interesting, the focus of this article is on building a VERY simple web crawler using Scrapy. With a certain degree of proficiency, Scrapy can be used to perform in different contexts, for different applications and different web sites, and since it all already comes in a well organized structure with several inbuilt functionalities, we don’t need to start every project from zero. This not only saves us time, but enables us to create professional and robust web crawlers.
You can check the complete code here.
And if you have any questions or suggestions, feel free to contact me!
References and more resources
Scrapy Tutorial - The official Scrapy tutorial
How to Crawl the Web Politely with Scrapy - Guidelines for using Scrapy in an ethical way
How to Scrape a Medium Publication: A Python Tutorial for Beginners - A very nice tutorial for web scraping Medium articles using BeautifulSoup instead of Scrapy
Selectors - Tutorial on XPath and CSS selectors using Scrapy

